
Probably Safe AI
A Case for Marginal Progress on Superalignment Theory

I entered the AI safety world in the Summer of 2022, after several years hanging around the periphery. The field was rapidly growing due to an influx of funding to EA from a soon to be disgraced cryptocurrency entrepreneur. There was a desperation for new blood and big new ideas about how to approach AI alignment. Full-time positions were bottlenecked by people to manage the new recruits, but the bar was low to get funding as an independent researcher. It seemed like a matter of time until those networks coalesced into mature organizations.
As an illustrative example, Scott Alexander of ACX ran the first iteration of a general grants program in early 2022. He reported that “The Long-Term Future Fund [LTFF] approached me and said ‘we will fund every single good AI-related proposal you get, just hand them to us, you don’t have to worry about it’. Then I had another person say ‘hand me the ones LTFF doesn’t want, and I’ll fund those’”.
Those days are long past. For starters, LTFF has since become funding constrained, and the ratio of qualified applicants to full-time positions is extreme. But even more importantly for understanding how the field has changed, the kinds of research being pursued have dramatically shifted. The number of people trying to develop methods to align superintelligence has dropped in both relative and absolute terms.
The Shift From Theory
In November 2022, less than three weeks after FTX went bankrupt, OpenAI released ChatGPT. It hit a million users in under five days, and soared to a hundred million within two months. AI quickly became a salient topic to the general public, as did its failures. There were jailbreaks and hallucinations; Sidney Bing threatened to break up a marriage. Where AI alignment had been largely conceptual and theoretical discussions targeted at superintelligence, there was now the demand for empirical experiments on how best to align existing models.
That’s not to say that before ChatGPT, the alignment community was ignoring existing models. People like Chris Olah had been working on the interpretability of existing models for years at that point. Redwood Research had just finished a large project to see if they could train a language model to completely avoid violent text (they couldn’t). However, working with current model was still thought of as a small subfield, sometimes called “prosaic alignment”. The rough consensus of the field was that it was good for some people to be working on current models, but that the main focus should be on developing techniques to align an arbitrarily powerful AI.
Since then, the ratio in the field has more than flipped. Almost all AI alignment research being done now is targeted at existing models. MIRI, which was once at the forefront of conceptual research, has now pivoted to policy work. You can get an idea of the magnitude of this shift by looking at the following request for proposals from Open Philanthropy, the largest AI alignment grantmaker. Only the final item includes developing methods aimed at actually aligning superintelligence.
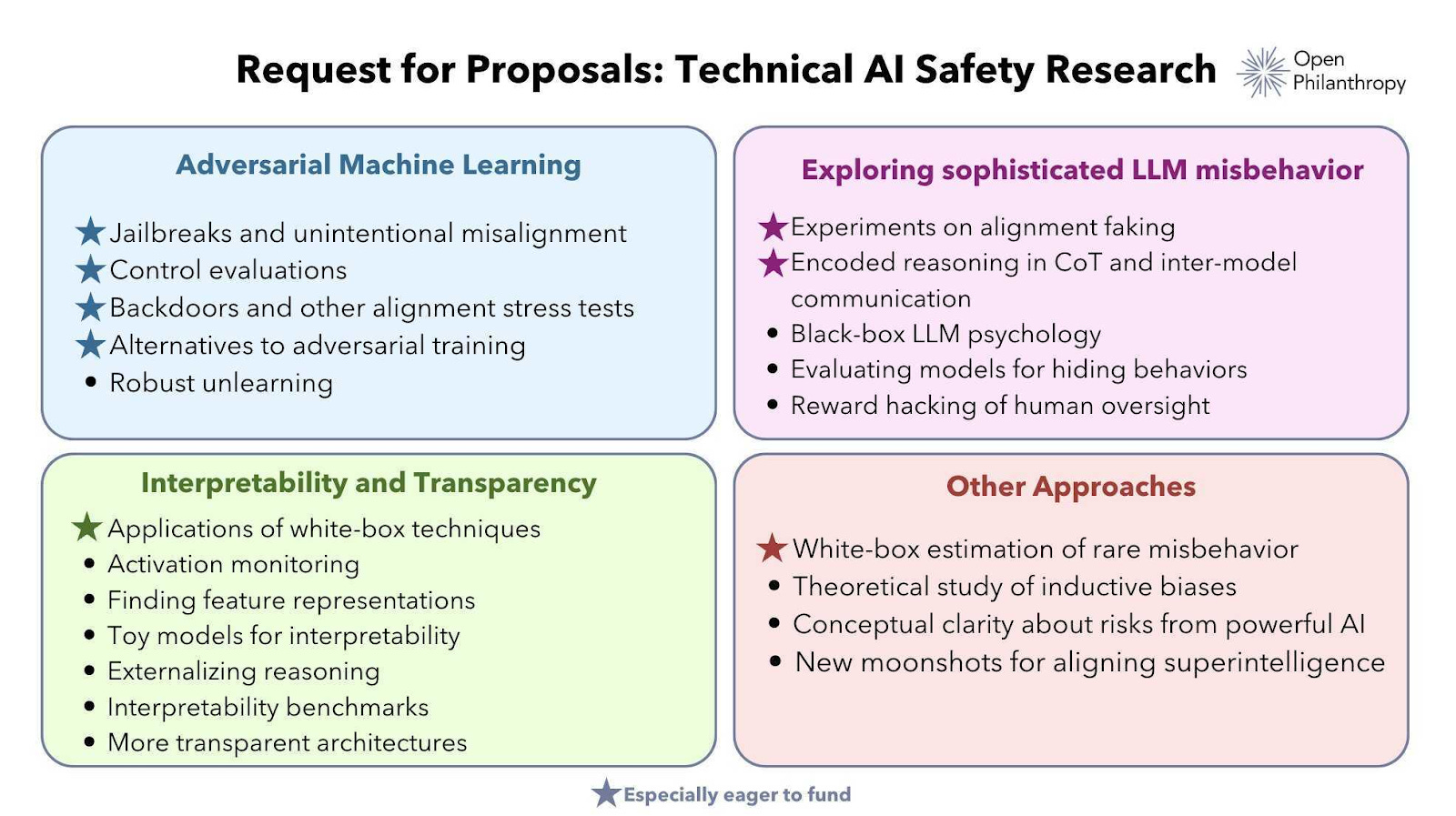
That’s not at all to say that Open Philanthropy is responsible for the current state of the field. Considering proposals aimed at aligning superintelligence at all is more than many organizations cover, and in my mind enormously valuable. Rather, I see what’s going on here as a chicken and egg problem. There are few opportunities to work on aligning superintelligence, so researchers choose different career paths. There are few agendas for aligning superintelligence, so grantmakers prioritize other research directions.
Beyond funders of non-profits, empirical work is overwhelmingly the focus of the safety teams at the major labs. While it is common for job postings to indicate that strong ML skills are a requirement but no background in AI safety is necessary, it would be truly surprising to see the reverse. This focus is understandable, as it is the kind of work that synergizes with their main product lines, and access to cutting edge models gives them a comparative advantage. I mention them here since such jobs are a notable fraction of the field (and often have the highest status/salary), so it represents a further shift in the makeup of research directions.
Another example of the state of the field that I would point to is the AI X-Risk Research Podcast (AXRP) from Daniel Filan, which I consider the best podcast for staying on top of AI alignment research. In the first eighteen episodes, before ChatGPT was released, the content was largely centered around theoretical approaches. Since then, most episodes have covered empirical work, along with policy work, evaluations, and forecasting. Like with Open Philanthropy’s funding areas, I don’t see the episode topic shift as a result of deliberate choices made by Daniel, but rather a pipeline issue. Almost all AI alignment research that could be covered is now on the empirical side.
Is this shift towards empirical safety research good? Certainly I think it’s a good thing that the proportion of empirical work is higher than it was when GPT-3 was released, although that’s a low bar. Empirical work is more valuable the greater the expectation that AGI will be structured and behave like systems today, which is often correlated with a short timeline to AGI. If you think AGI will differ at a deep level from today’s systems, for example like an agent pursuing a long-term goal, then the value of working on today’s systems goes down. There are issues like deceptive alignment that may not arise until it’s too late to do anything about them, and so have to be addressed proactively and can only be done in theory.
Another good argument in favor of empirical safety research is that if we can just align human-level AI empirically, we can have it do the theoretical research for us. On one hand, I think this is a completely valid argument, and people working on alignment from all perspectives should be prepared to use powerful AI to supplement or take over their work. On the other hand, I don’t see this as a good argument to focus overwhelmingly on empirical work. Having AI do our homework for us is putting a lot of eggs in one basket, and in scenarios with faster takeoff or where developers use AI to improve capabilities over safety, there may just not be time to have AI solve our issues before we face superintelligence. On top of that, doing theoretical work now can also help even if we eventually do get significant research from AI in the future, by laying out a plan for future AI to fill in, by providing examples of what good theoretical alignment work looks like, and by any transfer of understanding gained about future systems to current ones.
The Shift Within Theory
Within the set of people working on AI alignment theory, the majority of research is directed towards formalizing and understanding the problem. You can take a look at the tracks for the ILIAD conference to get an idea of what I mean. The first two tracks, on computational mechanics and causal learning theory, were about understanding neural networks and how they evolve over training. The second two tracks, on agent foundations and causal incentives, were about understanding how to describe and model agents. Notably absent from the conference was space for work addressed at solving challenges in aligning superintelligence. While an increased theoretical understanding of agents and their neural network substrates can certainly help develop solutions, I still believe that there is still plenty of room to work on them directly today.
The shift within theory has been less drastic than the shift from theoretical to empirical work. Agendas like agent foundations and causal incentives have been open areas of research for a long time, and have not noticeably changed in size. Here, the shift in field composition has been driven more by a reduction in work targeted at solutions.
Provably Safe AI is another theory-based agenda that some big names are pursuing. The goal of the program is to be able to generate a proof that an AI meets some specification, thus guaranteeing safety (what exactly that specification that guarantees safety will be is left open for now). In practice, Provably Safe AI often tries to verify properties of the outputs of the AI instead of the AI itself. For example, if the AI creates some code, then that code can be proven safe to run. Davidad notes that danger arises from the interaction of the AI(‘s outputs) and the broader world, so to be provably safe requires a high-fidelity model of the world as well.
The common thread through these approaches is that they are working towards a solution to AI alignment that is robust to unknown problems. Unless we deeply understand agents and deeply understand neural networks, how can we be confident that a proposed solution addresses all sources of risk? Taking that further, what we would really like is a mathematical proof showing that we will get our desired outcome. If we can get the chance of extinction from AGI to 0%, then that’s a worthy target.
Probably Safe AI
While a robust plan for alignment is a laudable goal, lowering the probability of extinction on the margin is also valuable. There are known problems that can be worked on, and which addressing would represent significant progress towards safe AI. While those problems remain unsolved, I think a comprehensive approach ruling out unknown problems should be a lower priority than targeted solutions for the issues we’re already aware of.
Which kind of problems am I talking about? Specifying a goal that would be safe to optimize for is a really big one at the core of the alignment problem. If you go in the direction of human approval, then you run into the eliciting latent knowledge (ELK) problem, where we want the model to generalize from the human feedback it receives to outcomes that are actually good rather than ones that the human merely perceives as good due to manipulation. ELK also provided examples of what work in the area could look like, through their prize contest. If you instead go in the direction of predictive accuracy as a goal to optimize for, then you run into issues like performative prediction where the model tries to manipulate the world to make it more predictable. I personally made some progress addressing that issue recently. Other approaches like inverse reinforcement learning or debate, as well as entirely new angles, are also good examples of approaches to solving this problem.
There are also problems that arise given a goal. Avoiding goal misgeneralization is a big one, and proposing training approaches that minimize the risk, or developing existing ideas like diversify and disambiguate would be helpful. Corrigibility and deceptive alignment are two major problems, though I would say they are largely the same problem, and progress on either by inventing training processes or regularization terms (e.g. the speed prior) would be extremely valuable.
Some examples of researchers working on approaches aimed at solving individual problems are Michael Cohen, Joar Skalse, and Yoshua Bengio’s lab. Michael works on what he calls “Solutions in Theory”, attempting to define any solution to key problems as a first step before taking constraints like implementability into consideration. Joar has historically focused on inverse reinforcement learning, but has a wider range of research interests and recently wrote a series of Alignment Forum posts describing his approach. Yoshua and many in his lab are working on Scientist AI, which I’d consider a bit of an edge case here, a proposal to avoid many issues in AI alignment by creating an AI without goals.
There’s a case against working to solve specific problems like the above, that says failure is overdetermined. It doesn’t matter if you find the perfect goal to give an AI without a way to ensure that’s the goal that is learned, and it doesn’t matter if you find the way to implant an arbitrary goal without knowing anything that’s safe to optimize for. Plus, anything that requires a hit to competitiveness won’t get implemented, anything too fragile won’t get implemented correctly, and weird stuff like anthropic capture or unknown unknowns could doom you anyway. If you believe that, then a bottom-up approach building from the foundations becomes necessary.
I don’t believe that though. I agree that progress needs to be made in several different areas of alignment, but it does not seem to me like there are so many challenges that failure solving any one problem is next to worthless. Rather, it seems to me like there are only a small handful of big problems, and so making progress on any of them would drastically simplify the overall issue.
On top of that, we don’t know how good a solution needs to be for it to make a difference. For example, with the ELK problem, it’s unclear how much the policy of optimizing for what humans perceive is favored over the policy of optimizing for what humans intend (if it’s favored at all), and so even minor progress has a chance of pushing past the tipping point. Similarly, it’s unclear how close to a goal like human approval is necessary to reach before it becomes self-reinforcing, so even small gains in delaying situational awareness and deceptive alignment could bring the learned goal past that threshold. Especially for theoretical issues where we won’t be able to test interventions until failure cannot be recovered from, the most we can say about whether a particular idea will work is “probably”.
The big picture summary of my view is that there are a small number of known theoretical problems that need to be solved for a full plan for AI alignment. The exact number of problems depends on the solutions to other problems (e.g. using predictive accuracy as the solution to goal specification introduces the new problem of performative prediction). For most of these problems, there is some chance they go well by default, although it is unlikely that all of them do so independently. For those issues that do not go well by default, any progress has some chance of passing the necessary threshold to ensure that it does.
If I had to sum it up in a single sentence, it would be “Develop interventions that in theory reduce the likelihood of known problems arising”. Put that way, it seems straightforwardly good, but existing research agendas directed towards that end are scarce. I think it would be useful to name that cluster of research directions for easy reference, since at the moment there is no good label.
My proposal would be to call this approach Probably Safe AI, in contrast to Provably Safe AI. Rather than aiming for 100% guaranteed safety, the goal of Probably Safe AI is to increase the probability of safe AI on the margin. This is done through theoretical work that helps address particular problems, even if it falls short of a comprehensive solution. Similarly, the problems addressed are the known issues in AI alignment, even if this does not eliminate unknown unknowns. The success criteria is a plan that we can say is probably safe, and where we feel that every problem that we’ve thought of has been addressed by some element of the plan.
One tool from Effective Altruism (EA) that I really like is the Importance, Tractability, Neglectedness (ITN) framework for cause prioritization, which says the best approaches score highly on all three metrics. The argument for the importance of Probably Safe AI is straightforward. Rogue AI causing human extinction would be catastrophic, so a plan to reduce the chance of that would be valuable. Even for the more empirically-minded, who think of AI alignment as more of an engineering problem, having a plan that works in theory should be reassuring and provide practical guidance.
The main point of this post was to establish the neglectedness of the approach. There are not many people working on alignment theory, few within it are working towards solutions, and the research that is targeting solutions tends to be comprehensive rather than marginal. This means that additional people working in the area will be disproportionately valuable.
For many EA-adjacent people, neglectedness is something that applies on the global level rather than a local one. There are relatively few people worldwide working on a problem, but EA donors have stepped up to address that. You get to have your cake and eat it too, working on a neglected problem but within an ecosystem set up to support you. That applies less so here, where Probably Safe AI is also neglected on a local level. There is less funding and fewer opportunities to do this kind of work, but that makes it even higher impact to do so anyway.
The big question about Probably Safe AI is whether this approach is actually tractable. If not, then the importance and neglectedness don’t matter. Somewhat unfortunately, I think the answer is ambiguous. It’s not clearly tractable, since if we knew the exact steps to take we would have already done so. But it’s not clearly less tractable than other research problems either. The number of people who have actually tried to generate solutions to alignment theory problems is tiny, especially if you filter down to those who worked full time on it, and most of their approaches were highly correlated with each other. It seems eminently possible that there is medium-low hanging fruit when coming from novel directions, or just progress from more eyeballs on the problems picking up on something that others missed.
Given those considerations, I personally judge Probably Safe AI to be the direction in which I can make the greatest impact in reducing risk from AI. My next post will go into greater detail on what an overarching plan for alignment looks like, what the open problems are, what the current state of progress on them looks like, and what’s left to do.